EC2 Auto Scalingを試してみた
AWS公式のEC2 Auto Scalingのハンズオンをやってみたのでメモしておきます。
ハンズオンに必要なリソースはCloud Formationで準備されるので、 Auto Scalingの設定に集中して取り組めました。
Auto Scaling以外にもたくさんのハンズオンがあり、下記リンク先に一覧があります。 サービスの雰囲気を掴むのに役立つので一通りやってみたいなと思っています。
EC2 Auto Scalingとは
あらかじめ設定した条件に応じて、EC2インスタンスを自動的に追加・削除することで 可用性の維持とコスト最適化をはかることができるサービスです。
Auto Scalingの設定の流れ
Auto Scalingの設定は下記の流れになります。
起動テンプレートを作成Auto Scalingグループを作成- 自動スケーリングの設定
1. 起動テンプレートを作成
Auto Scalingによって追加・削除されるインスタンスの設定を定義します。 主に下記のような項目を指定します。
- AMI
- インスタンスタイプ
- ネットワーク設定
2. Auto Scalingグループの作成
Auto Scalingグループを作成します。主に下記の項目を指定します。

3. 自動スケーリングの設定
最後にスケーリングを実行する条件を設定します。
作成したAuto Scalingグループを開き、自動スケーリングのタブから設定できます。
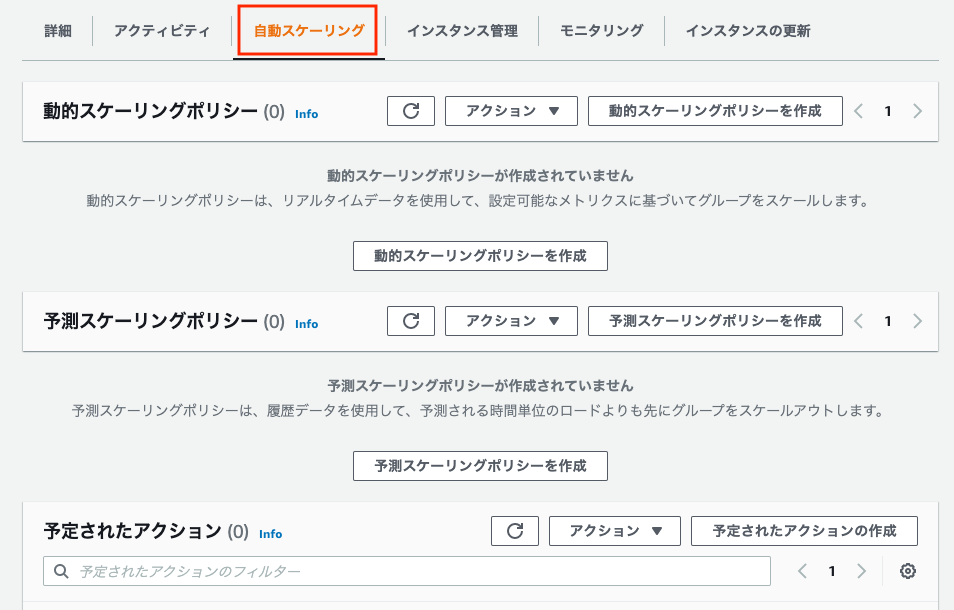
スケーリングする方法にはいくつかありますが、ハンズオンでは下記を実際に試します。
- スケジュールスケーリング(予定されたアクション)
- 動的スケーリング
スケジュールスケーリング
設定したスケジュールに基づいてインスタンスの増減を行なう仕組みです。 特定の時間帯にアクセスが集中するなど、負荷がある程度予測できる場合に利用します。
反復条件として「毎日」「毎週」以外にも、Cron形式で指定することもできます。
ハンズオンの中では特定の時刻に一度だけ実行されるスケーリング設定を行ないました。
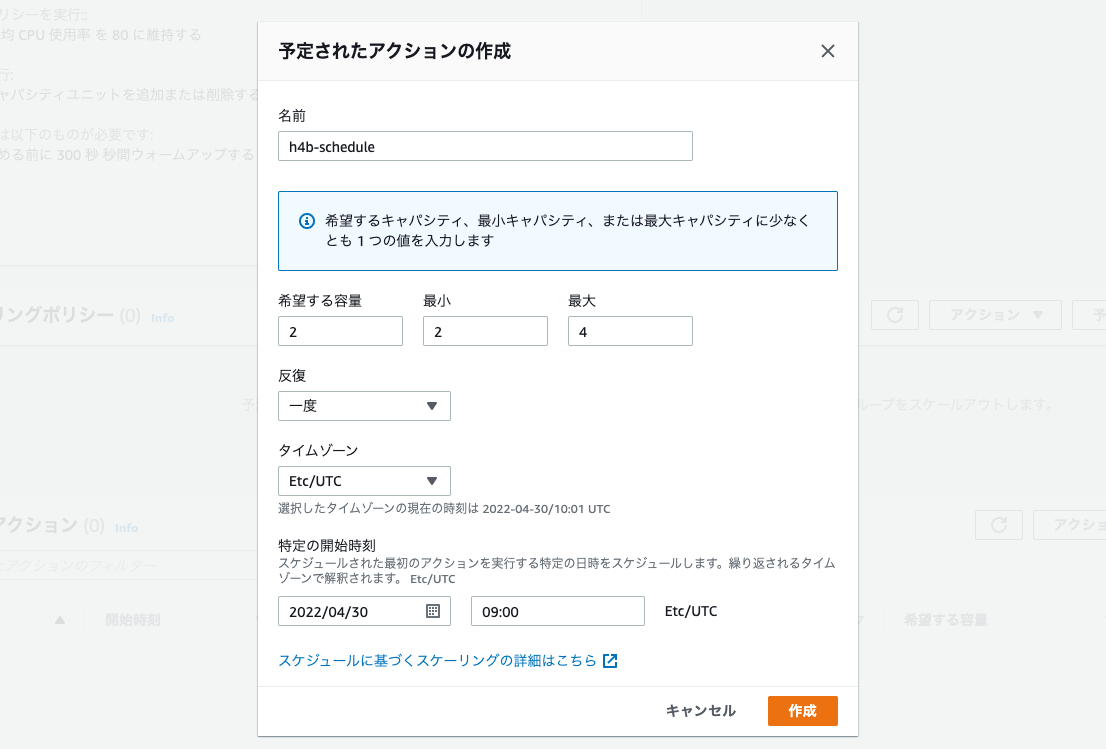
動的スケーリング
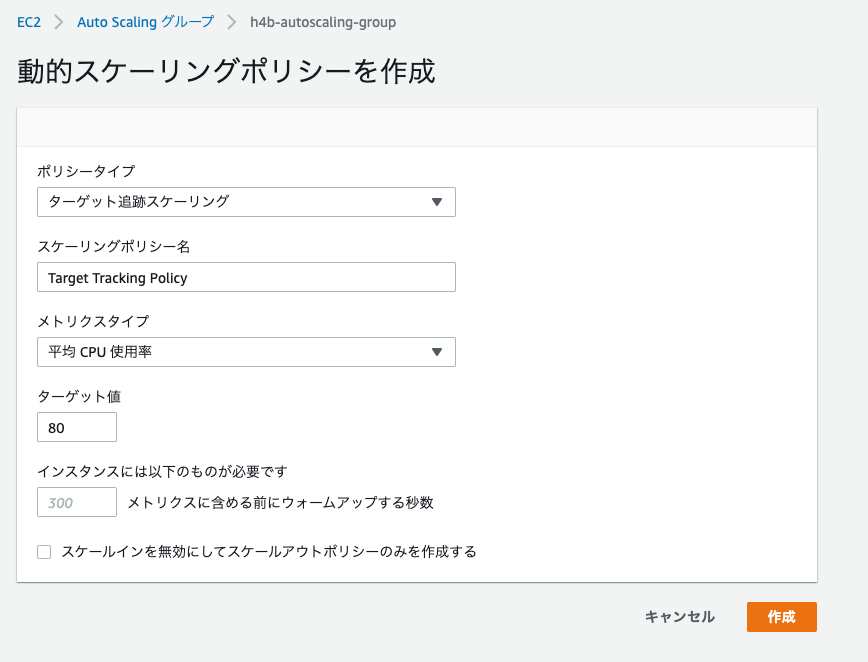
設定した閾値に基づいてインスタンスの増減を行なう仕組みです。 負荷が予測できない場合に利用します。
スケーリングには数分かかるので、急激なアクセス増加(スパイクアクセス)での利用には注意が必要とのことです。
ハンズオンの中では「ターゲット追跡スケーリング」として、平均CPU使用率が閾値を超えたらインスタンス台数を増やす設定を行ないました。
異常なインスタンスの置き換え
インスタンスに障害が発生して、維持したい最小台数を下回った時もAuto Scalingがインスタンスを追加してくれます。
ハンズオンでは、最小キャパシティが「2台」に設定されている環境で、 1台のインスタンスを停止させた時の様子を確認しました。
まとめ
EC2 Auto Scalingのハンズオンをやってみました。 負荷状況に応じてインスタンスの増減を自動でやってくれるのは便利ですね。
一方で、インスタンスに固有の値を持たせると、スケールイン時にインスタンスが破棄されたときにその値も一緒に消えてしまいます。
アプリケーションのログなどはインスタンスに保持せず、外に出しておく設計が必要だと感じました。
Stream DeckからNature Remo APIを実行する
前回試したNature Remo APIをStream Deckから実行してみます。
普段からPCの作業でStream Deckを使っていたので、 自室の家電もこれで制御できると便利だなと思っていたところでした。
調べてみるとStream DeckのプラグインにHTTPリクエストを投げられるものがあったので、 Nature Remo APIを叩いて自室の照明をON/OFFするボタンを作ってみました。
環境
- macOS Monterey (Ver 12.3.1)
- Stream Deck (ver5.2.1)
Stream Deckとは
様々なショートカットを各ボタンに割り当てることができるデバイスです。 ボタンの数は6個、15個、32個のものがありますが、ページを切り替えたりフォルダで階層を作ったりと物理的なボタンの数以上の機能を割り当てられるのでかなり便利です。
使い方の例
- よく使うアプリケーションを起動する
- スクリーンショットを撮る
- 頻繁に入力するテキストをボタンで呼び出す
- 動画の再生・停止
- 音量調整・ミュート
Web Requestsのインストール
Stream Deckのプラグインとして、Web Requestsをインストールします。
このプラグインを使えば、キーを押した時にあらかじめ設定しておいたURLにHTTPリクエストを投げることができます。
Stream Deckのストアにアクセスし、
プラグイン > 開発ツールにあるWeb Requestsをインストールします。

照明を制御するAPIの確認
照明をON/OFFするために以下のNature Remo APIを使います。
https://swagger.nature.global/#/default/post_1_appliances__appliance__light
https://api.nature.global/1/appliances/{appliance}/light
{appliance}には制御する機器のIDを指定します。
IDの確認方法
Nature Remoのスマホアプリで操作する機器の名称(nickname)を確認します。
今回の場合は「照明」という名称(nickname)です。

次に下記エンドポイントにGETリクエストを送信します。
https://api.nature.global/1/appliances/
JSONでレスポンスが返ってきます。操作したい機器のnicknameが含まれているIDが{appliance}に指定する値です。


Stream Deckにボタンを作成する
機器のIDがわかったら、Stream Deckのアプリを起動して
Web Requestsを実行するボタンを作成します。

照明ONボタンの作成
まず、照明をONにするボタンを作成します。
URLのbuttonパラメータの値としてonを指定します。
トークンはHeadersに指定します。Authorization: Bearerを忘れないように記述してください。
| 項目名 | 値 |
|---|---|
| タイトル | 照明ON |
| URL | https://api.nature.global/1/appliances/{appliance}/light?button=on |
| Method | POST |
| Headers | Authorization: Bearer {TOKEN} |

照明OFFボタンの作成
次に照明をOFFにするボタンも作成します。
今度はbuttonパラメータにoffを指定します。
| 項目名 | 値 |
|---|---|
| タイトル | 電気のOFF |
| URL | https://api.nature.global/1/appliances/{appliance}/light?button=off |
| Method | POST |
| Headers | Authorization: Bearer {TOKEN} |

アイコンは好きなものを選びます。 ボタンが作成できたら、実際にボタンを押下して動作確認します。
まとめ
Nature Remo APIをStream Deckから実行してみました。ボタンを押して実際に部屋の電気を点けたり消したりできた時は感動しますね。
これでPCの操作だけでなく、自室の家電制御もStream Deckからできるようになったので万能感があって良いです。
Nature Remo APIを使ってみた
自室でNature Remoを使って部屋の電気やエアコンを制御しています。 普段はスマホアプリで操作していますが、APIがあるとのことで試してみました。
今回はトークンを生成し、Nature Remoのユーザー名(nickname)を取得するAPIを実行してみます。
環境
- macOS Monterey (Ver 12.3.1)
- Postman (Ver 9.15.2)
- Nature Remo
Nature Remoとは
スマホアプリで操作できる赤外線リモコンです。
Nature Remoを自宅のWi-Fiに接続しておくことで、 エアコンやテレビなどの家電を外出先からでも操作することができます。
「指定した時刻になったら部屋の電気をつける」など、 条件をトリガーに家電制御することもできる便利なデバイスです。
Nature Remo APIについて
概要はNature Remo Developer Pageに記載があります。
Nature Inc. | Nature Developer Page
API実行のために、HTTPのリクエストヘッダにトークンを付与する必要があります。
Authorization: Bearer {TOKEN}
トークンはhome.nature.globalから申請できます。
トークンの取得方法
home.nature.globalにアクセスしたら、
Nature Remoの初期セットアップ時に作成したアカウントのメールアドレスを入力します。

ログイン用のURLが入力したメールアドレスに届くのでログインします。

アクセス許可が求められるので許可します。

Generate access tokenをクリックすると、トークンが生成されます。
トークンの取り扱いには十分に注意してください。

トークンはこの段階でしか表示されません。
失念したらRevokeして新しく発行します。

PostmanでAPIを叩いてみる
トークンが取得できたので実際にユーザー名を取得するAPIを実行します。
各APIの仕様はここにあります。
https://swagger.nature.global/
実行にはPostmanを使いました。
| 項目名 | 設定値 |
|---|---|
| URL | https://api.nature.global/1/users/me |
| access_token | 取得したトークン値 |
トークンはPostmanのAuthorizationタブで設定します。
TypeにOAuth2.0を選択し、Access TokenにAvailable Tokensと取得したトークンを設定します。

実行するとユーザー名(nickname)を取得できました。

AWS SSOのアクセス許可セットのセッション期間を変更する
AWS SSOにはアクセス許可セットごとにセッションの有効期限があります。 有効期限が過ぎると、別画面に遷移した時などにセッションの有効期限切れ画面が出ます。
画面の指示通り、表示されているURLをクリックすることで新たにセッションを開始することができます。

ただ、運悪く設定作業中に有効期限が切れると、保存時にこの画面が表示されて設定がやり直しになったりします。
デフォルトでは1時間に設定されているので、変更したいと思います。
セッション期間を変更する
AWS SSOにアクセスし、アクセス許可セットを開きます。

セッションの有効時間を変更したいアクセス許可セットを選択します。

編集をクリックします。

セッション期間を任意の時間に変更します。
設定できる時間は最小で1時間、最大で12時間です。

変更後、設定を保存をクリックします。
まとめ
AWS SSOのアクセス許可セットのセッション期間を変更しました。 アクセス許可セットごとに設定が必要になります。
1時間だと結構頻繁にセッションが切れるように感じるので、不便にならない程度の時間に設定しておくと良いと思います。
AWS SSOのSAML認証でSIEM on Amazon OpenSearch Serviceにログイン
前回、SIEM on Amazon OpenSearch Serviceをパブリックアクセス(Amazon VPC外)にデプロイしました。 今回はAWS SSOのSAML認証でシングルサインオンします。
これにより、OpenSearch Serviceにユーザーを作る必要がなくなり、AWS SSOのアカウント管理に一元化できます。 また、ログイン先がAWS SSOに統一されますし、AWS SSO側の設定で2要素認証を必須にしておけばセキュリティも強化できます。
前提
- AWS Control Towerを有効化している
- 管理アカウントにAWS SSOがある
- 監査アカウントにSIEM on Amazon OpenSearch Serviceが有効
AWS SSOでSAML認証設定(1)
まず、管理アカウントにログインします。
AWS SSOのアプリケーションを開きます。

新規アプリケーションの追加からカスタムSAML2.0 アプリケーションの追加を選択します。
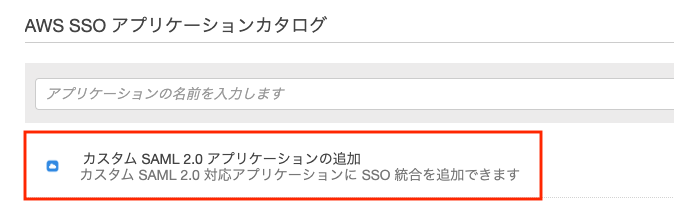
表示名はAWS SSOのダッシュボードに表示される名前なので分かりやすい表記にしておきます。
例:SIEM on Amazon OpenSearch Service

AWS SSO SAML メタデータファイルをダウンロードします。
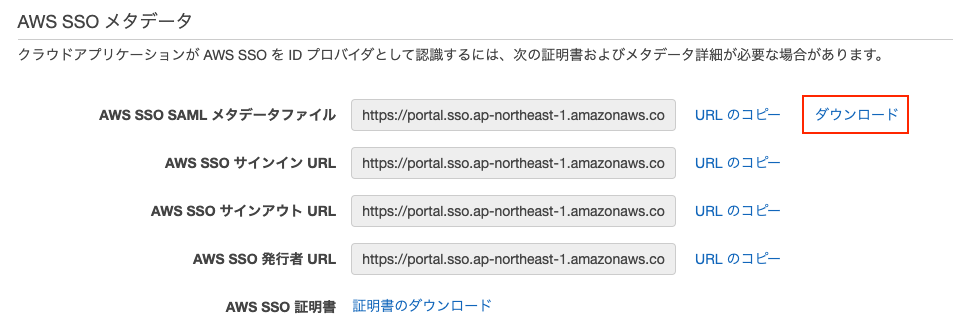
画面はこのままにしておき、次にOpenSearch Service側の設定に移ります。
OpenSearch ServiceでSAML認証設定(1)
次に、監査アカウントにログインします。
OpenSearch Serviceにあるドメインaes-siemを開き、セキュリティ設定を編集します。
SAML認証を有効化にチェックを入れます。

サービスプロバイダエンティティID(図中①)とIdPによって開始されたSSO URL(図中②)をメモしておきます。

またXMLファイルからインポートで先ほどAWS SSOからダウンロードしたXMLファイルを選択します。

ここまで完了したら、画面はこのままにしておき、中断していたAWS SSOの設定に戻ります。
AWS SSOでSAML認証設定(2)
管理アカウントのAWS SSOに戻ります。
アプリケーションのプロパティにメモしておいた値をそれぞれ入力し保存します。
各属性の対応に注意してください。(上図と下図の番号は対応させています。)
アプリケーション ACS URLにIdPによって開始されたSSO URL(図中②)
アプリケーションSAML対象者にサービスプロバイダーエンティティID(図中①)

ここまで完了できたら設定の保存をクリックします。

属性マッピングの設定
次に、属性マッピングのタブを開き、2つの属性を追加します。
| アプリケーションのユーザー属性 | この文字列値またはAWS SSOの…(省略) |
|---|---|
| Subject | ${user:subject} |
| Role | ${user:groups} |

OpenSearch Serviceにログインできるユーザーの設定
割り当て済みユーザーのタブを開きます。
この設定により、OpenSearch Serviceにログインを許可するAWS SSOのユーザー or グループを指定できます。

許可するユーザー or グループにチェックを入れてユーザーの割り当てをクリックします。
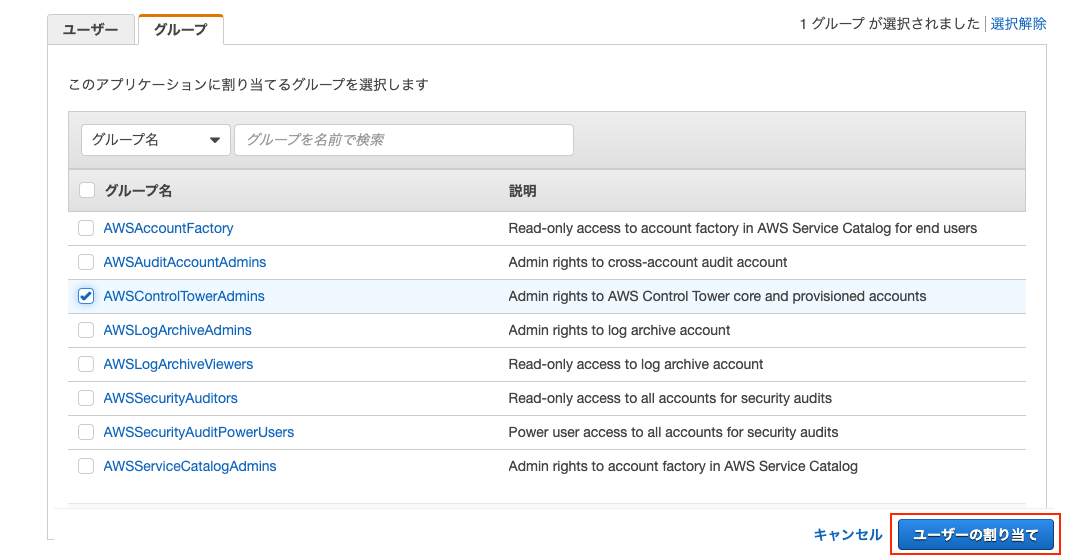
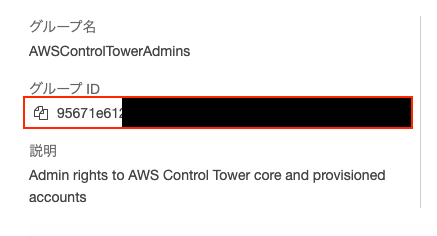
設定後、割り当てたユーザーのIDをメモしておきます。
OpenSearch ServiceでSAML認証設定(2)
監査アカウントのOpenSearch Serviceに戻り、下記項目を設定します。
| 設定項目 | 設定値 |
|---|---|
| SAML マスターバックエンドロール | 割り当てたユーザーorグループのID |
| ロールキー - オプション | Role |
ここまで設定できたら変更の保存をクリックします。

設定確認
AWS SSOのダッシュボードにアクセスすると、
アプリケーション設定で指定した表示名の名称でアイコンが表示されます。

アイコンをクリックしてOpenSearch Serviceにログインできれば設定完了です。

まとめ
2つのAWSアカウントを交互に行き来して設定する点がややこしかったです。 別ブラウザを使ったり、シークレットモードを使うなどして、両方ともログインした状態にしておくと便利かと思いました。
これまではSIEM環境へのログイン先をAWS SSOに一元化できたので管理面でも楽になりました。
参考
SIEM on Amazon OpenSearch Serviceのデプロイ手順
AWS Control Tower環境にSIEM on Amazon OpenSearch Serviceをデプロイした時のまとめです。
SIEM on Amazon OpenSearch Serviceとは
AWS環境におけるログを集約し可視化してくれるOSSのSIEMソリューションです。 デプロイ手順やログ集約のための設定もドキュメントに記載されていて簡単に始めることができます。
詳しくは公式リポジトリにあるドキュメントを確認してください。 github.com
環境
- AWS Control Tower環境で用意される監査(Audit)アカウント
- 東京リージョン
- OpenSearch Serviceはパブリックアクセス(Amazon VPC外)に配置
手順
AWS Control Towerのようなマルチアカウント環境下に展開する場合AWS CDKを使います。
ドキュメントのAWS CDKによるデプロイの通り実施します。
https://github.com/aws-samples/siem-on-amazon-opensearch-service/blob/main/docs/deployment_ja.md
1. EC2インスタンスを立てる
- t2.micro
- Admin権限を持ったロールをインスタンスに付与する
2. EC2インスタンスに接続
インスタンスが起動したことを確認したら、SSHで接続します。
ssh -i <PEMファイル> ec2-user@xxx.xxx.xxx.xxx
3. EC2インスタンスに開発環境やソースコードをダウンロードする
cd sudo yum groups mark install -y "Development Tools" sudo yum install -y amazon-linux-extras sudo amazon-linux-extras enable python3.8 sudo yum install -y python38 python38-devel git jq tar sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 git clone https://github.com/aws-samples/siem-on-amazon-opensearch-service.git
4. 環境変数の設定
AWS_DEFAULT_ACCOUNTには監査アカウントのAWSアカウントID(12桁)を、
AWS_DEFAULT_REGIONにはデプロイ先のリージョンを指定します。
今回は東京リージョンにデプロイしたので下記となります。
export CDK_DEFAULT_ACCOUNT=123456789012 export AWS_DEFAULT_REGION=ap-northeast-1
5. AWS Lambdaデプロイパッケージの作成
cd siem-on-amazon-opensearch-service/deployment/cdk-solution-helper/ chmod +x ./step1-build-lambda-pkg.sh && ./step1-build-lambda-pkg.sh
6. AWS CDKの環境準備
chmod +x ./step2-setup-cdk-env.sh && ./step2-setup-cdk-env.sh source ~/.bash_profile
7. AWS CDKでのインストールオプションの設定
cd ../../source/cdk/ source .env/bin/activate cdk bootstrap
8. 設定ファイルのコピー
パブリックアクセス(Amazon VPC外)にデプロイする場合の設定ファイルの雛形をコピーします。
cp cdk.json.public.sample cdk.json
9. 設定ファイルの編集
AWS Organizationsを使っている場合、組織IDと各AWSアカウントのIDを設定ファイルに記載します。 設定ファイル内にサンプルも記載されているので、それを参考に書きます。
nano cdk.json
"organizations": {
"org_id": "o-12345678",
"management_id": "111111111111",
"member_ids": ["222222222222", "333333333333"]
},
org_idには組織IDを指定します。AWS Organizationsにアクセスすると記載があります。
management_idには管理アカウントのIDを指定します。AWS Control Towerを有効化したアカウントのことです。
member_idsには管理アカウント以外の各AWSアカウントのIDを指定します。AWS SSOのダッシュボードで一覧できます。
10. JSONファイルのバリデーションを実行
JSONが表示され、特段エラーが出なければOKです。
cdk context --j
11. AWS CDKの実行
parametersオプションにSIEM環境へのアクセスを許可するIPアドレスや、SIEMで検知したアラートの送信先となるメールアドレスを指定します。
cdk deploy --parameters AllowedSourceIpAddresses="xxx.xxx.xxx.xxx" --parameters SnsEmail="hogehoge@example.jp"
約30分たつとデプロイが完了します。
ターミナル上にOutputsとしてSIEM環境へのアクセス情報が表示されます。
Outputs: aes-siem.DashboardsAdminID = ******** aes-siem.DashboardsPassword = ******* aes-siem.DashboardsUrl = ******* aes-siem.RoleDeploy = *******
なお、ここで見落としてもCloudFormationのスタックからaes-siemを開いて、「出力」タブを確認すると記載があります。

SIEM環境(OpenSearch Dashboards)にアクセス
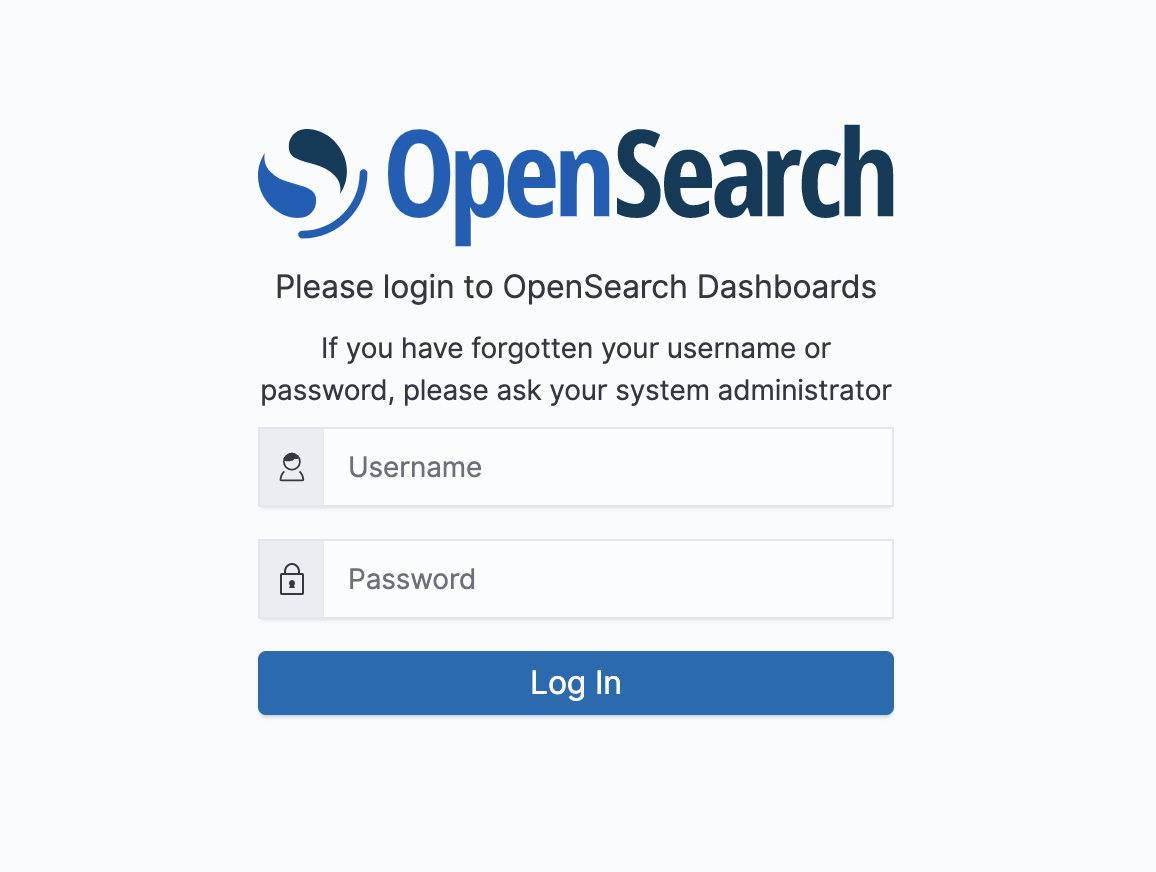
aes-siem.DashboardsUrlに記載のURLにアクセスするとOpenSearch Dashboardsのログイン画面が表示されます。
DashboardsAdminIDとDashboardsPasswordを入力してログインします。
OpenSearch Dashboards > Dashboardsに定義済みのダッシュボードが表示されます。

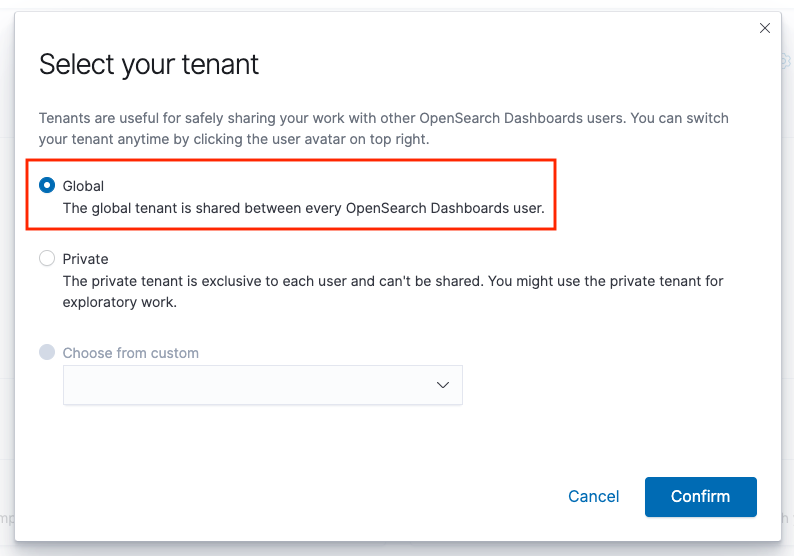
定義済みのダッシュボードが見当たらない場合
右上のユーザーアイコンからSwitch tenants > Globalに切り替えます。

ログの取り込み方法
SIEM環境にログを取り込むにはそれぞれ集約設定が必要になります。
S3にaes-siem-[AWS_Account]-logというバケットが作成されており、ここにログを集めることで可視化されるようになります。
ログの取り込み方もドキュメントに記載があります。
まとめ
公式の手順通りに進めると問題なくデプロイできました。
ただ、OpenSearch ServiceはEC2インスタンスのように停止ができません。 構築したまま置いておくと結構費用が掛かるので検証が終わって不要な場合は忘れずに削除しておきます。
詳細はドキュメントの「クリーンアップ」に記載があります。
OpenSearchをDocker Composeで起動してみた
AWSのOpenSearch Serviceを使うことがあり、自分のPC上でOpenSearchを動かしてみました。
環境
- macOS Monterey (Ver 12.3)
- Docker Desktop (Ver 4.6.1)
インストール
Docker Composeを使って起動します。 事前にDockerがインストールされていることを確認しておきます。
$ docker --version Docker version 20.10.13, build a224086 $ docker-compose --version Docker Compose version v2.3.3
OpenSearchの公式サイト(https://opensearch.org/downloads.html)から
docker-compose.ymlを任意の場所にダウンロードし、下記コマンドを実行します。
$ docker-compose up
OepnSearchのイメージが取得されコンテナが起動します。
Webブラウザからhttp://localhost:5601にアクセスすると
無事OpenSearch Dashboardsが起動していることを確認できました。
OpenSearchの概要
公式ドキュメントの導入部分を読んだので、最後に用語をメモしておきます。 opensearch.org
クラスターとノード
インデックスとドキュメント
- OpenSearchではデータはインデックスごとに管理される
- 各インデックスはJSON形式のドキュメントの集合
プライマリシャードとレプリカシャード
- クラスター内の各ノードにデータを分散させるため、インデックスは複数のシャードに分割される
- ノード障害に備えて、プライマリシャードごとにレプリカシャードが作られる
- レプリカシャードはプライマリシャードとは別のノードで管理される
- レプリカシャードがあることで検索速度も改善する
-
Amazon OpenSearch Serviceでは「ドメイン」と表現されています。Amazon OpenSearch Service ドメインの作成と管理 - Amazon OpenSearch Service↩